
Scikit-learn이란?
Scikit-learn은 Python 기반의 머신러닝 라이브러리로, 데이터 분석과 예측 모델 구축을 간단하고 효율적으로 수행할 수 있도록 다양한 도구를 제공합니다. 특히 지도 학습(Supervised Learning), 비지도 학습(Unsupervised Learning), 데이터 전처리(Preprocessing), 모델 평가(Evaluation), 그리고 모델 선택(Model Selection) 등을 포괄적으로 지원하며, 학계와 산업계에서 널리 사용되고 있습니다.
1. Scikit-learn의 개요
- 출시 연도: 2007년 시작, 2010년 첫 릴리스.
- 설계 목표:
- 간결하고 효율적인 머신러닝 알고리즘 제공.
- 쉬운 사용성과 풍부한 기능 제공.
- 기반 기술:
- NumPy, SciPy, matplotlib 등의 과학 컴퓨팅 라이브러리에 기반.
- Python 환경에서 자연스럽게 통합 가능.
- 오픈소스: BSD 라이선스를 따르며, 누구나 무료로 사용 및 수정 가능.
2. Scikit-learn의 주요 특징
(1) 폭넓은 알고리즘 지원
Scikit-learn은 다양한 머신러닝 알고리즘을 포함하며, 데이터 분석의 주요 과정을 쉽게 구현할 수 있습니다.
- 지도 학습: 선형 회귀, 로지스틱 회귀, 서포트 벡터 머신(SVM), 결정 트리, 랜덤 포레스트, K-최근접 이웃(KNN), 신경망(MLPClassifier) 등.
- 비지도 학습: K-평균, 계층적 군집화, 주성분 분석(PCA), 독립 성분 분석(ICA), 가우시안 혼합 모델(GMM) 등.
- 강화 학습: 제한적이지만 일부 환경에서 사용 가능.
- 특화된 알고리즘: 아웃라이어 탐지(Isolation Forest), 특성 선택 및 추출.
(2) 데이터 전처리
데이터를 머신러닝 모델에 적합한 형태로 변환할 수 있는 다양한 도구를 제공합니다.
- 스케일링: 표준화(StandardScaler), 정규화(Normalizer), Min-Max 스케일링(MinMaxScaler).
- 결측값 처리: SimpleImputer.
- 인코딩: OneHotEncoder, LabelEncoder.
- 특성 변환: PolynomialFeatures, Binarizer.
(3) 모델 선택 및 평가
- 교차 검증: cross_val_score(), GridSearchCV를 통해 모델의 일반화 성능을 평가.
- 성능 평가 지표: 정확도(Accuracy), 정밀도(Precision), 재현율(Recall), F1 스코어, ROC-AUC 등.
- 하이퍼파라미터 튜닝: 그리드 탐색(Grid Search), 랜덤 탐색(RandomizedSearchCV).
(4) 데이터셋
- 내장 데이터셋: Iris, Boston Housing, Digits, Wine 등 소규모 데이터셋 제공.
- 외부 데이터 로드: Pandas와 호환되어 외부 CSV, Excel 등의 데이터를 쉽게 처리 가능.
(5) 통합과 확장성
Scikit-learn은 다른 Python 생태계 도구(Numpy, Pandas, Matplotlib 등)와 자연스럽게 연동되며, 필요에 따라 사용자 정의 기능을 추가할 수 있습니다.
3. Scikit-learn의 주요 구성 요소
(1) 데이터 준비
데이터를 처리하고 전처리하는 단계는 머신러닝 프로젝트의 핵심입니다.

(2) 모델 학습 및 평가
Scikit-learn에서는 모델 정의, 학습, 평가가 간단히 이루어집니다.

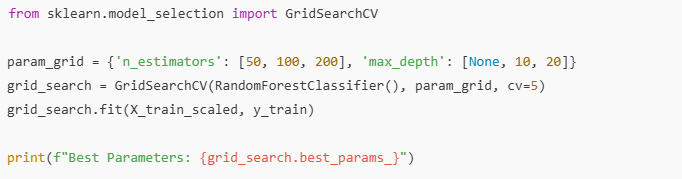
(3) 하이퍼파라미터 튜닝
하이퍼파라미터 최적화를 통해 모델 성능을 향상시킬 수 있습니다.
(4) 파이프라인
전처리와 모델 학습을 하나의 파이프라인으로 구성하여 작업을 자동화합니다.

4. Scikit-learn의 장점과 단점
장점
- 간결한 API: Pythonic 스타일로 설계되어 사용법이 직관적입니다.
- 풍부한 알고리즘 지원: 거의 모든 머신러닝 알고리즘이 포함되어 있습니다.
- 탄탄한 커뮤니티: 활발한 개발과 업데이트, 풍부한 문서와 튜토리얼.
- 데이터 전처리 도구: 데이터 준비와 변환에 필요한 다양한 기능 제공.
- 효율성: Cython으로 구현되어 높은 성능을 보장합니다.
단점
- 딥러닝 지원 부족: 딥러닝과 같은 복잡한 신경망 모델은 지원하지 않습니다(TensorFlow, PyTorch 사용 필요).
- 대규모 데이터셋 처리 제한: 매우 큰 데이터셋에서는 효율성이 떨어질 수 있습니다.
- 병렬 처리 제한: 일부 알고리즘만 병렬 처리를 지원합니다.
5. 주요 활용 사례
- 예측 모델링
- 예: 판매 예측, 질병 진단, 고객 이탈 분석.
- 군집화
- 예: 고객 세분화, 문서 분류, 이상 탐지.
- 차원 축소
- 예: 데이터 시각화, 속도 향상을 위한 데이터 압축.
- 자연어 처리
- 예: 텍스트 분류, 키워드 추출.
6. Scikit-learn의 경쟁 도구와 비교
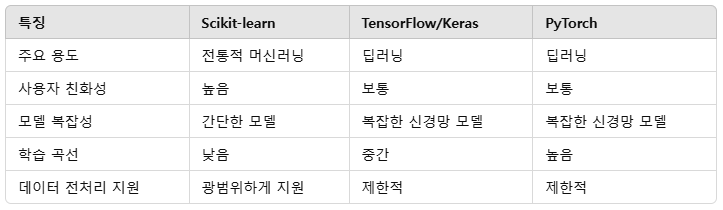
Scikit-learn은 간결하면서도 강력한 머신러닝 라이브러리로, 전통적인 머신러닝 프로젝트를 효율적으로 수행할 수 있는 도구를 제공합니다. 특히 데이터 전처리부터 모델 학습, 평가, 최적화까지의 전체 워크플로를 간단한 코드로 구현할 수 있다는 점에서 강력합니다. 딥러닝이 아닌 전통적 머신러닝을 다룰 때 가장 적합한 선택지 중 하나이며, Python 생태계와의 뛰어난 통합성을 제공합니다.